
Emphatic AI Agent
Dev Vora / April 30, 2025
I had the opportunity to work on the development of an emphatic AI agent to respond with more precision to specific comments that users provided them.
Developing this emphatic AI agent was the most unique project I worked on over this semester. I got the opportunity to learn a lot more about machine learning, specifically by applying my skills to it.
We were working with an existing project from the previous semester, so we could look through their findings and learnings to understand if we wanted to move forward with their approach, or start fresh but apply their learnings.
Our group decided that it would be a better learning experience to start from scratch. We approached this problem with a multi-model approach described below:
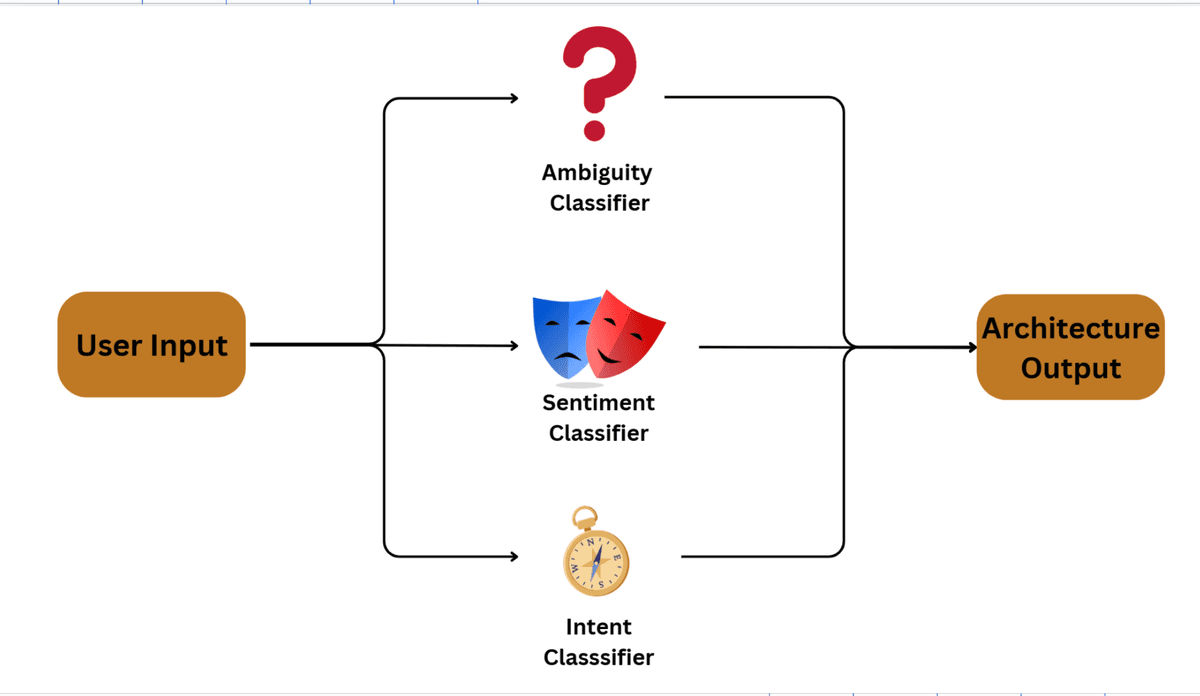
- The ambiguity classifier had the core function of ensuring that the model was on the right track, and that there was no ambiguity between phrases. For example, if someone asked "what is a crane" with no other context, we would need to ask the user again if they were referring to the animal, machinery, or something else.
- The sentiment classifier was used to identify how the user was feeling about their prompt. This helped with specific ambiguous use cases such as the following: "My dog of 15 years just died, but I'm so happy", where the model responded by saying: "I'm sorry to hear about your loss. It's unusual to hear someone feeling happy about their pet passing away. Could you share more about what you're feeling right now?"
- Intent classification helped us identify how to serve the response to the user, we had a few intents to classify (precise intent, curious intent, navigational intent, support/help intent, etc.) which we categorized based on certain words in the input.
I worked on the intent classfier, which I developed using a LinearSVC model. This model seems like an unusual choice compared to the regular BERT based approach, but since our dataset was synthetically generated, we wanted to make a model that was effective for the amount of data that we were given.
During the development process, I encountered a few issues related to the dataset itself. First, I selected around 18 classes to identify to, but realized that these classes had some overlap. I eventually shortened these down to 7 classes.
Next, the issue was that these classes had sparse data. I wanted to make sure that I highlighted phrases with the same meaning, but different phrases which is why I synthetically generated, then manually modified, and added these modified phrases back into the dataset.
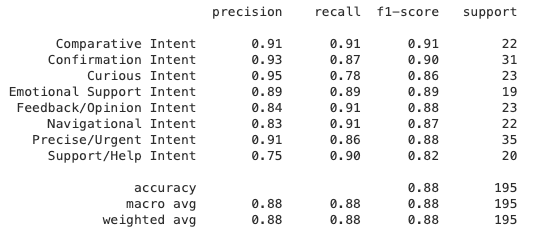
After repeating this process, the accuracy of the model went from about 71% to 88%, and was more applicable to actual user-input phrases.
For more in-depth analysis on the accuracy, check out the image below:
Next, I worked on setting up the UI and backend, along with deploying it. The backend was set up on an Apache server served by our UTM VM (configured by someone from our tech department), and I deployed the frontend on Vercel (since it was developed using Nextjs and React).
Although I can't share the source code, we have the website served online which you can view for yourself!
P.S. if you noticed, we actually have 3 different spellings for the project. We used "emphatic", "empathic", and "empathetic" interchangably, without realizing which one was which. Turns out, the correct spelling for what our model accomplishes is "emphatic"... which means "showing or giving emphasis; expressing something forcibly and clearly." 😅